
|

|

|

|
| Sandro Pezzelle ILLC, University of Amsterdam |
Ionut-Teodor Sorodoc Universitat Pompeu Fabra, Barcelona |
Aurelie Herbelot CIMeC, University of Trento |
Raffaella Bernardi CIMeC, DISI, University of Trento |
Quantifiers in a Multimodal World: Hallucinating Vision with Language and Sound
NAACL-HLT Workshop on Cognitive Modeling and Computational Linguistics 2019
[pdf] [bib]
Testoni, A., Pezzelle, S., Bernardi, R.
Inspired by the literature on multisensory integration, we develop a computational model to ground quantifiers in perception. The model learns to pick out of nine quantifiers (‘few’, ‘many’, ‘all’, etc.) the one that is more likely to describe the percent of animals in a visual auditory input containing both animals and artifacts. We show that relying on concurrent sensory inputs increases model performance on the quantification task. Moreover, we evaluate the model in a situation in which only the auditory modality is given, while the visual one is ‘hallucinated’ either from the auditory input itself or from a linguistic caption describing the quantity of entities in the auditory input. This way, the model exploits prior associations between modalities. We show that the model profits from the prior knowledge and outperforms the auditory-only setting.
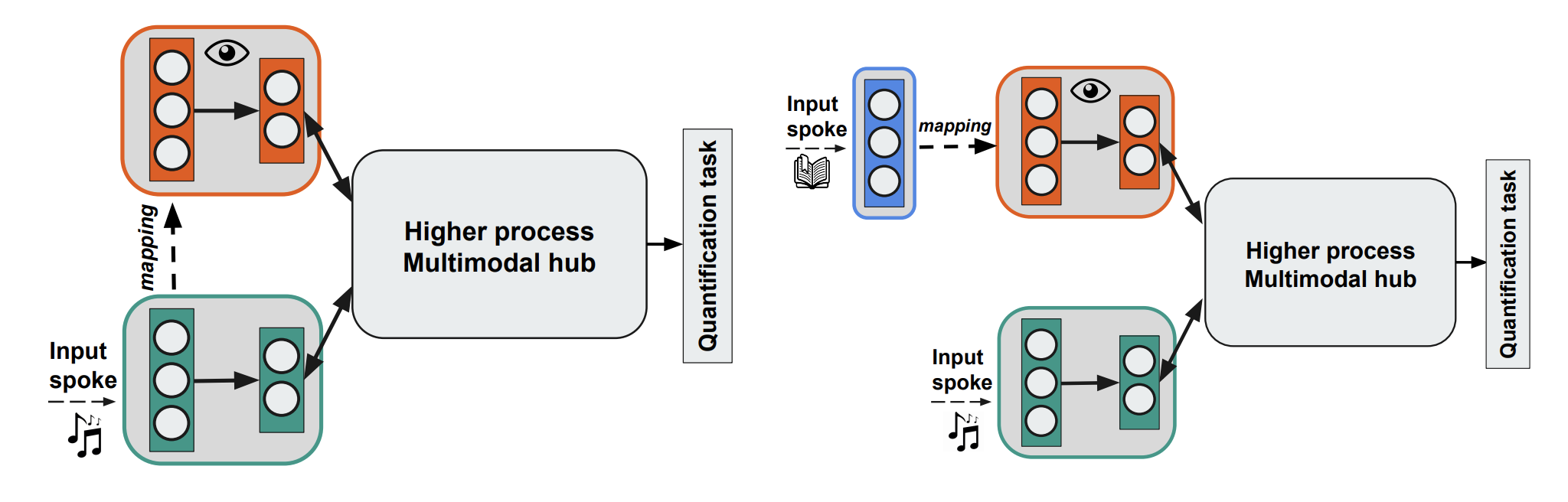
@inproceedings{testoni2019quantifiers,
author={Testoni, Alberto and Pezzelle, Sandro and Bernardi, Raffaella},
title={Quantifiers in a Multimodal World: Hallucinating Vision with Language and Sound},
booktitle={Proceedings of the Workshop on Cognitive Modeling and Computational Linguistics},
pages={105--116},
year={2019}
}
Probing the Mental Representation of Quantifiers
Cognition
[pdf] [bib]
Pezzelle, S., Bernardi, R., Piazza, M.
In this study, we investigate the mental representation of non-numerical quantifiers (‘some’, ‘many’, ‘all’, etc.) by comparing their use in abstract and in grounded perceptual contexts. Using an approach similar to that used in the number domain, we test whether (and to what extent) such representation is constrained by the way we perceive the world through our senses. In two experiments, subjects either judged the similarity of quantifier pairs (presented as written words) or chose among a predetermined list of quantifiers the one that best described a visual image depicting a variable number of target and non-target items. The results were rather consistent across experiments, and indicated that quantifiers are mentally organized on an ordered but non-linear compressed scale where the quantifiers that imply small quantities appear more precisely differentiated across each other compared to those implying large quantities. This fits nicely with the idea that we construct our representations of such symbols mainly by mapping them to the representations of quantities that we derive from perception.
@article{pezzelle2018probing,
author={Pezzelle, Sandro and Bernardi, Raffaella and Piazza, Manuela},
title={Probing the mental representation of quantifiers},
journal={Cognition},
volume={181},
pages={117--126},
year={2018}
publisher={Elsevier},
}
Some of them can Be Guessed! Exploring the Effect of Linguistic Context in Predicting Quantifiers
ACL 2018
[pdf] [bib] [data&code] [poster] [arxiv]
Pezzelle, S., Steinert-Threlkeld, S., Bernardi, R., Szymanik, J.
We study the role of linguistic context in predicting quantifiers (‘few’, ‘all’). We collect crowdsourced data from human participants and test various models in a local (single-sentence) and a global context (multi-sentence) condition. Models significantly out-perform humans in the former setting and are only slightly better in the latter. While human performance improves with more linguistic context (especially on proportional quantifiers), model performance suffers. Models are very effective in exploiting lexical and morpho-syntactic patterns; humans are better at genuinely understanding the meaning of the (global) context.

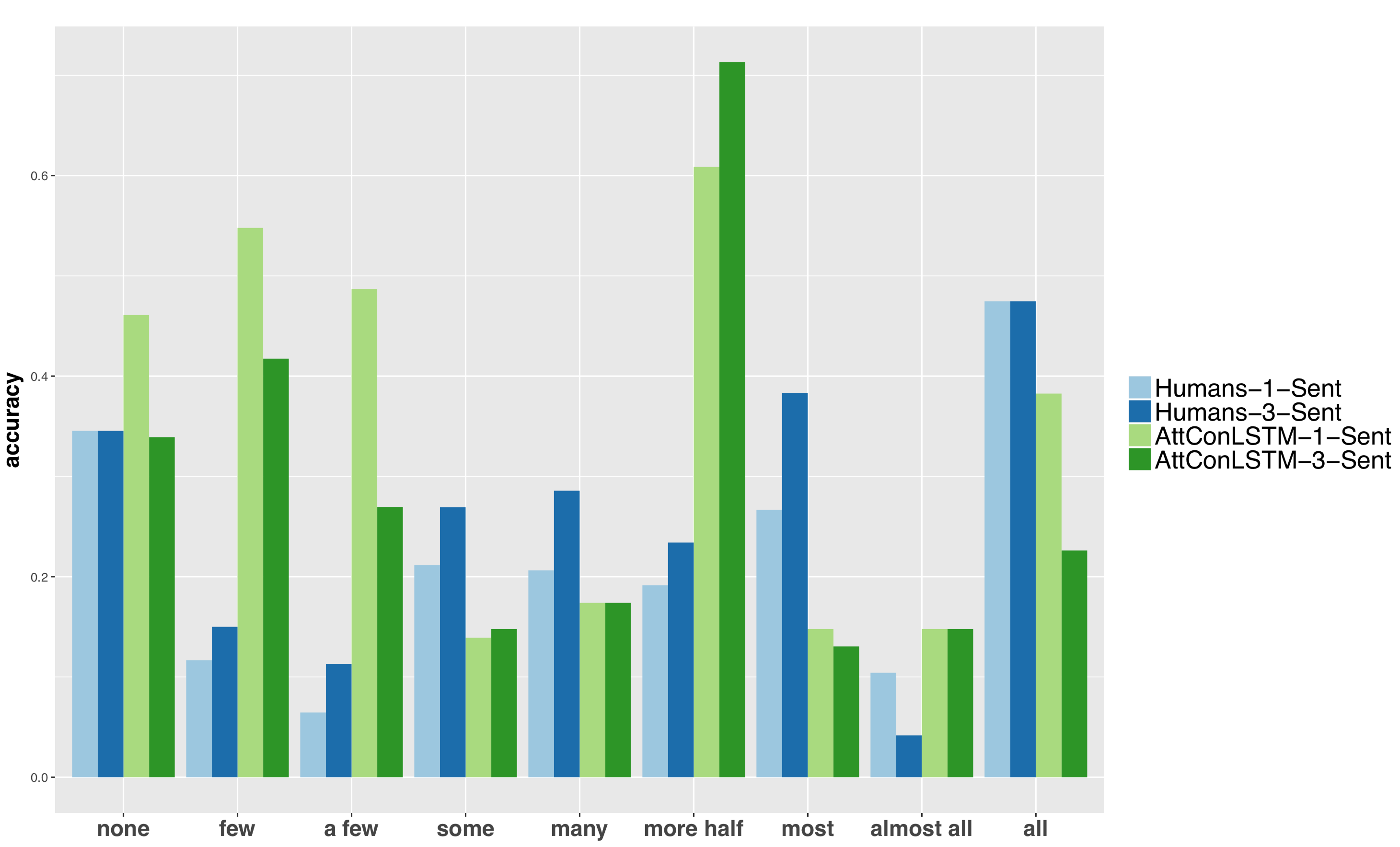
@InProceedings{P18-2019,
author={Pezzelle, Sandro and Steinert-Threlkeld, Shane and Bernardi, Raffaella and Szymanik, Jakub},
title={Some of Them Can be Guessed! Exploring the Effect of Linguistic Context in Predicting Quantifiers},
booktitle={Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)},
year={2018},
publisher={Association for Computational Linguistics},
pages={114--119}
address={Melbourne, Australia},
url={http://aclweb.org/anthology/P18-2019}
}
Comparatives, Quantifiers, Proportions: A Multi-Task Model for the Learning of Quantities from Vision
NAACL-HLT 2018
[pdf] [bib] [data&code] [slides] [poster] [arxiv]
Pezzelle, S., Sorodoc, I., Bernardi, R.
The present work investigates whether different quantification mechanisms (set comparison, vague quantification, and proportional estimation) can be jointly learned from visual scenes by a multi-task computational model. The motivation is that, in humans, these processes underlie the same cognitive, non-symbolic ability, which allows an automatic estimation and comparison of set magnitudes. We show that when information about lower-complexity tasks is available, the higher-level proportional task becomes more accurate than when performed in isolation. Moreover, the multi-task model is able to generalize to unseen combinations of target/non-target objects. Consistently with behavioral evidence showing the interference of absolute number in the proportional task, the multi-task model no longer works when asked to provide the number of target objects in the scene.
@InProceedings{pezzelle2018,
author={Pezzelle, Sandro and Sorodoc, Ionut-Teodor and Bernardi, Raffaella},
title={Comparatives, Quantifiers, Proportions: a Multi-Task Model for the Learning of Quantities from Vision},
booktitle={Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers)},
year={2018},
publisher={Association for Computational Linguistics},
pages={419--430}
address={New Orleans, Louisiana},
url={http://aclweb.org/anthology/N18-1039}
}
Learning Quantification from Images: A Structured Neural Architecture
Journal Natural Language Engineering 2018
[pdf] [bib] [data] [code] [arxiv]
Sorodoc, I., Pezzelle, S., Herbelot, A., Dimiccoli, M., Bernardi, R.
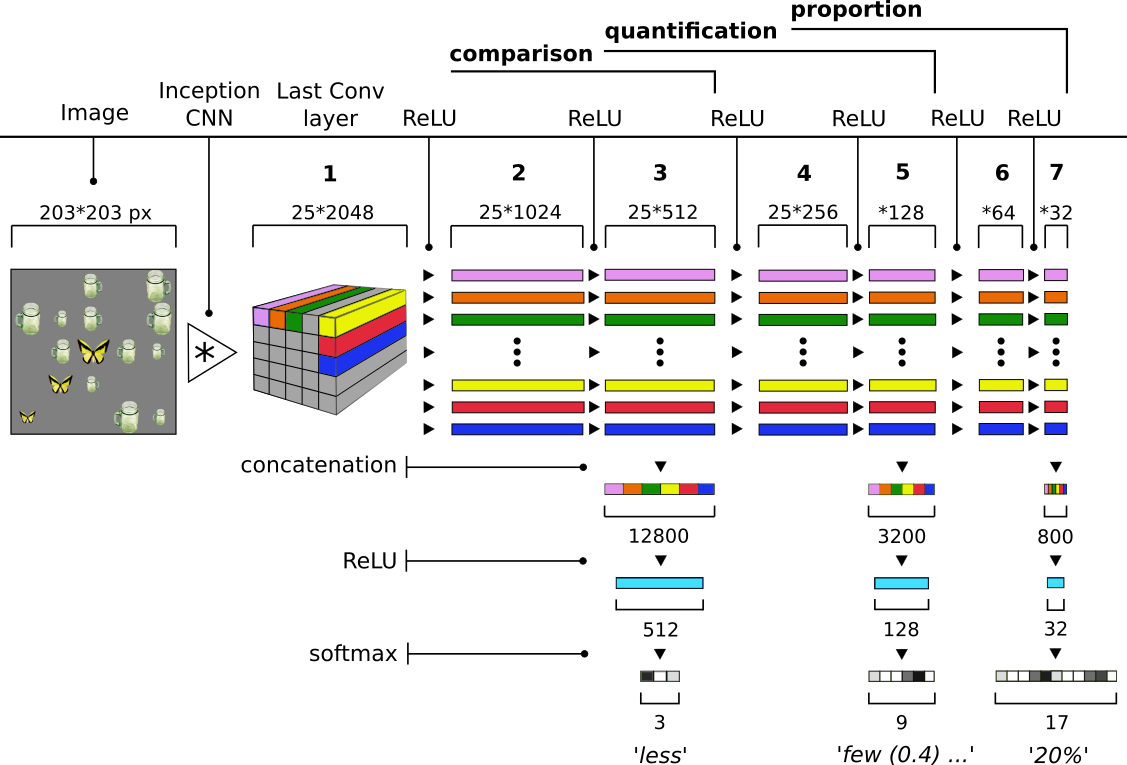
Major advances have recently been made in merging language and vision representations. Most tasks considered so far have confined themselves to the processing of objects and lexicalised relations amongst objects (content words). We know, however, that humans (even pre-school children) can abstract over raw multimodal data to perform certain types of higher-level reasoning, expressed in natural language by function words. A case in point is given by their ability to learn quantifiers, i.e. expressions like few, some and all. From formal semantics and cognitive linguistics we know that quantifiers are relations over sets which, as a simplification, we can see as proportions. For instance, in most fish are red, most encodes the proportion of fish which are red fish. In this paper, we study how well current neural network strategies model such relations. We propose a task where, given an image and a query expressed by an object-property pair, the system must return a quantifier expressing which proportions of the queried object have the queried property. Our contributions are twofold. First, we show that the best performance on this task involves coupling state-of-the-art attention mechanisms with a network architecture mirroring the logical structure assigned to quantifiers by classic linguistic formalisation. Second, we introduce a new balanced dataset of image scenarios associated with quantification queries, which we hope will foster further research in this area.
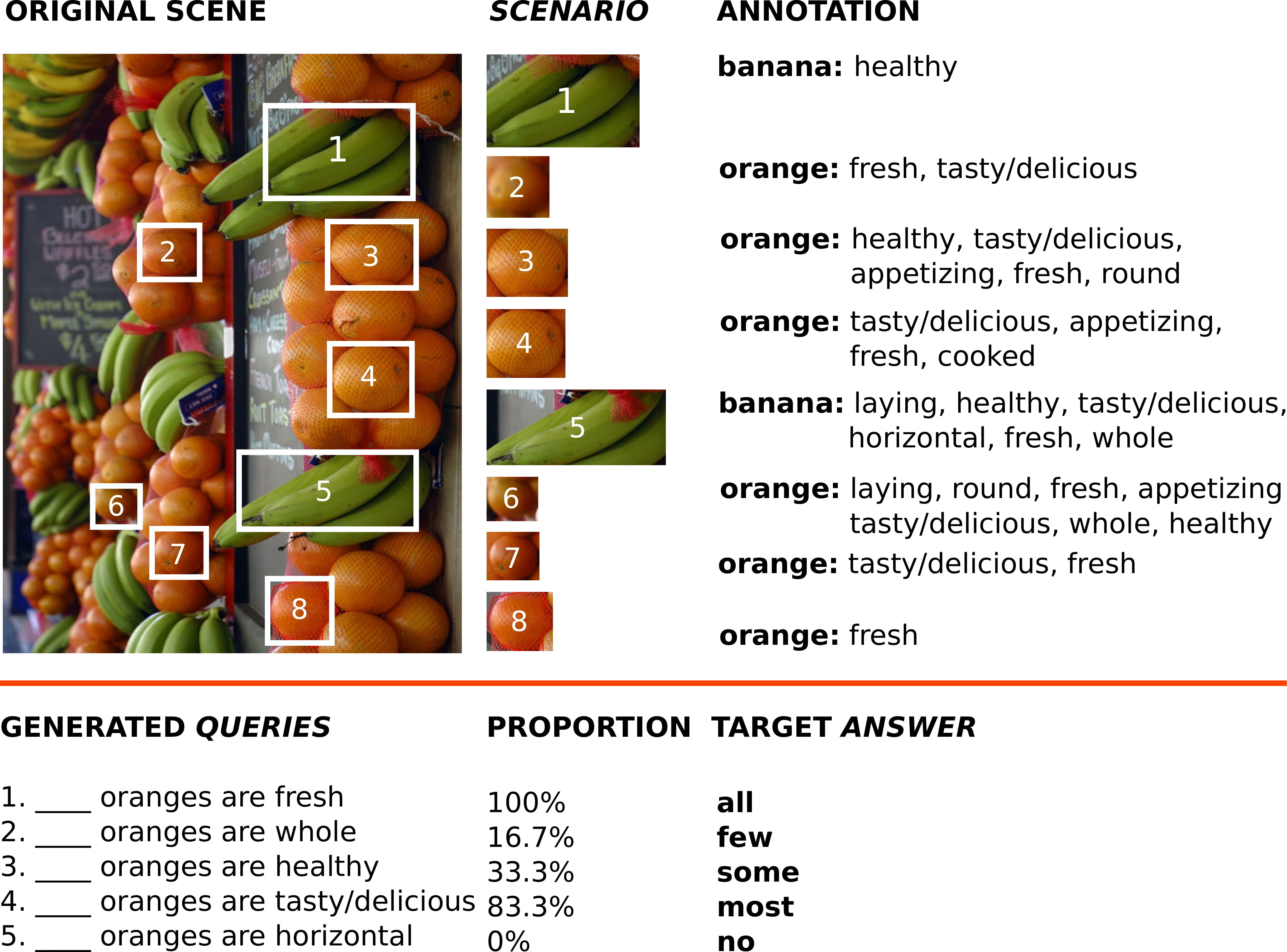
@article{sorodoc2018,
author={Sorodoc, Ionut and Pezzelle, Sandro and Herbelot, Aur{\'e}lie and Dimiccoli, Mariella and Bernardi, Raffaella},
title={Learning quantification from images: A structured neural architecture},
DOI={10.1017/S1351324918000128},
journal={Natural Language Engineering},
year={2018},
publisher={Cambridge University Press},
pages={1–30}
}
Be Precise or Fuzzy: Learning the Meaning of Cardinals and Quantifiers from Vision
EACL 2017
[pdf] [bib] [poster] [slides] [arxiv]
Pezzelle, S., Marelli, M., Bernardi, R.
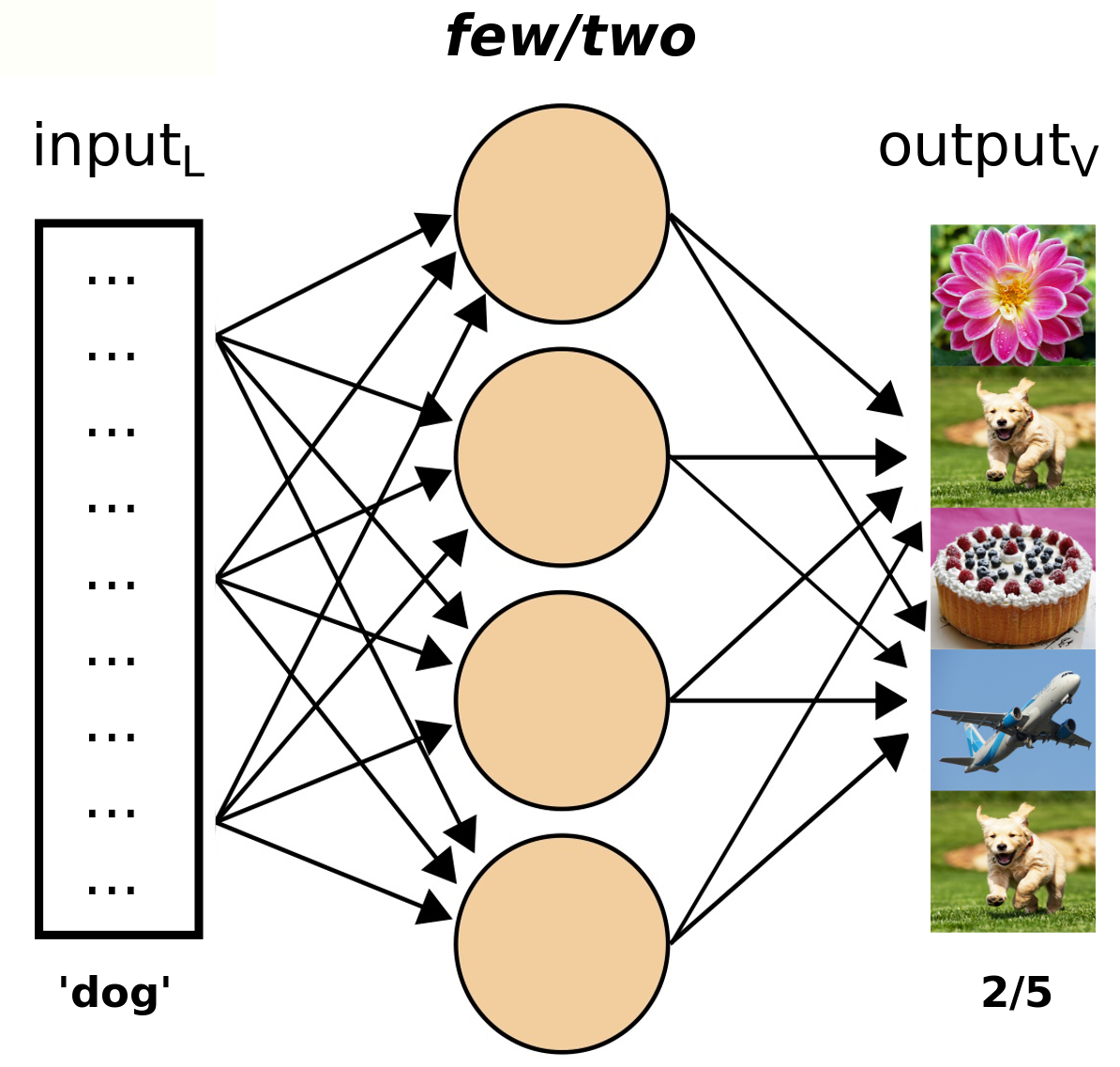
People can refer to quantities in a visual scene by using either exact cardinals (e.g. one, two, three) or natural language quantifiers (e.g. few, most, all). In humans, these two processes underlie fairly different cognitive and neural mechanisms. Inspired by this evidence, the present study proposes two models for learning the objective meaning of cardinals and quantifiers from visual scenes containing multiple objects. We show that a model capitalizing on a ‘fuzzy’ measure of similarity is effective for learning quantifiers, whereas the learning of exact cardinals is better accomplished when information about number is provided.

@InProceedings{pezzelle2017,
author={Pezzelle, Sandro and Marelli, Marco and Bernardi, Raffaella},
title={Be Precise or Fuzzy: Learning the Meaning of Cardinals and Quantifiers from Vision},
booktitle={Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers},
month={April},
year={2017},
address={Valencia, Spain},
publisher={Association for Computational Linguistics},
pages={337--342}
}
“Look, Some Green Circles!”: Learning to Quantify from Images
ACL Workshop on Vision and Language 2016
[pdf] [bib] [poster] [slides]
Sorodoc, I., Lazaridou, A., Boleda, G., Herbelot, A., Pezzelle, S., Bernardi, R.
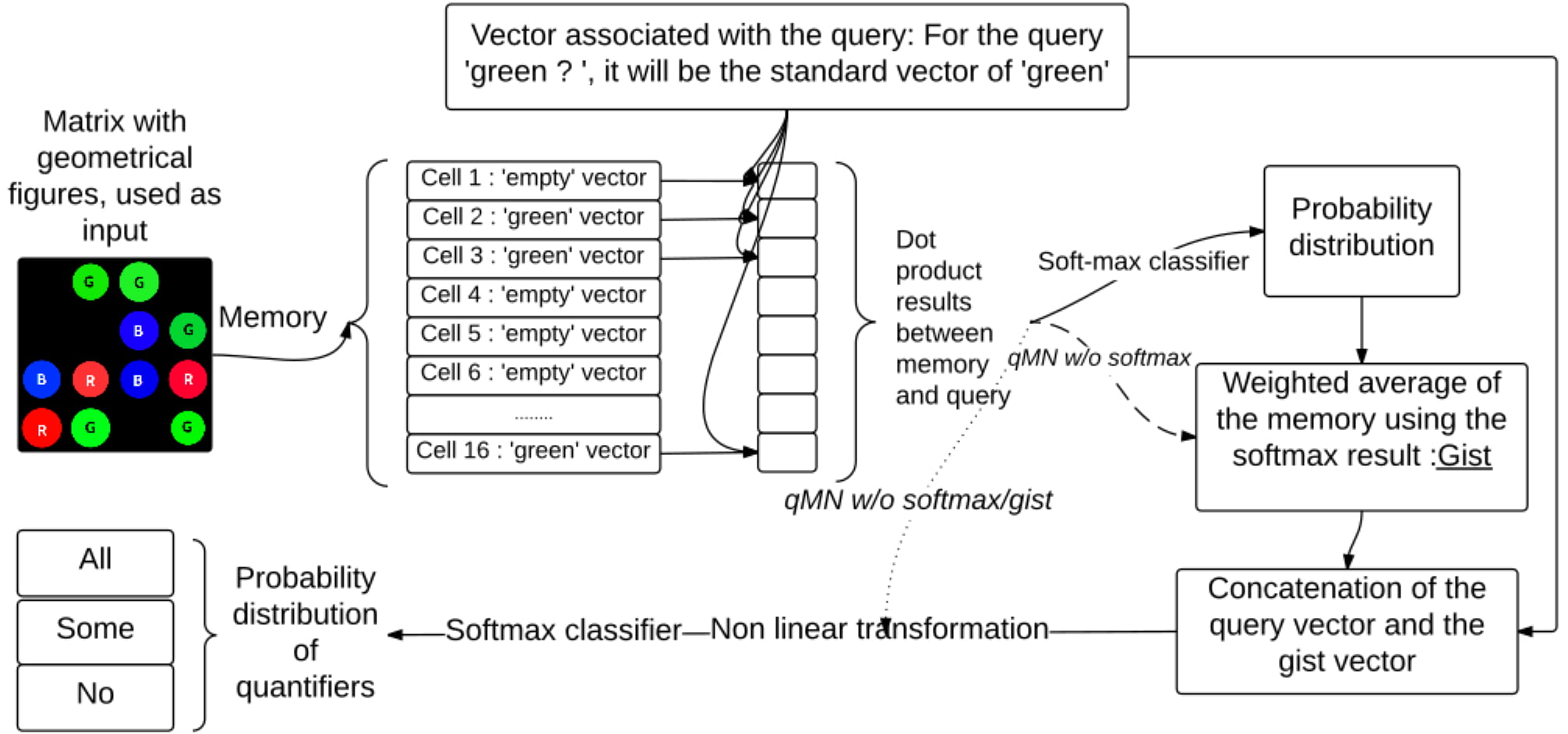
In this paper, we investigate whether a neural network model can learn the meaning of natural language quantifiers (no, some and all) from their use in visual contexts. We show that memory networks perform well in this task, and that explicit counting is not necessary to the system’s performance, supporting psycholinguistic evidence on the acquisition of quantifiers.
@inproceedings{sorodoc2016look,
title={“Look, some green circles!”: Learning to quantify from images},
author={Sorodoc, Ionut and Lazaridou, Angeliki and Boleda, Gemma and Herbelot, Aur{\'e}lie and Pezzelle, Sandro and Bernardi, Raffaella},
booktitle={Proceedings of the 5th Workshop on Vision and Language},
pages={75--79},
year={2016}
}
Collaborators
| Gemma Boleda Universitat Pompeu Fabra, Barcelona |
Mariella Dimiccoli Universitat de Barcelona |
Angeliki Lazaridou Google DeepMind, London |
Marco Marelli University of Milan-Bicocca |
| Manuela Piazza CIMeC, University of Trento |
Shane Steinert-Threlkeld University of Amsterdam |
Jakub Szymanik University of Amsterdam |
Alberto Testoni CIMeC, University of Trento |